Talkie-1930:碾压史前 AI 基准测试

目录
从历史尘封的页面中诞生的一个人工智能,通过清除现代基准测试的所有污垢而引人注目。名为Talkie-1930的130亿参数开放权重语言模型,使用1931年1月1日前出版的2600亿token文本进行训练。书籍、报纸、科学期刊、专利和诉讼记录等公共领域来源被使用。这个严格的截止日期从一开始就防止测试数据泄露到训练集中,并使AI泛化研究完美无缺。由Claude Sonnet 4.6持续触发运行的模型,在talkie-lm.com/chat地址上对所有人开放。
Talkie-1930的数据清洗和训练过程
由Nick Levine、David Duvenaud、Alec Radford领导的非营利团队,在Anthropic的计算支持下发布了两个检查点:用于自动补全的基本版本和针对聊天的指令调整版本,两者均在Apache 2.0许可下于Hugging Face上可用。该模型从未听说过互联网、冷战、青霉素或像加密货币这样的现代ALT期货;医学知识限于1930年代。
模型的历史预测和金融建议
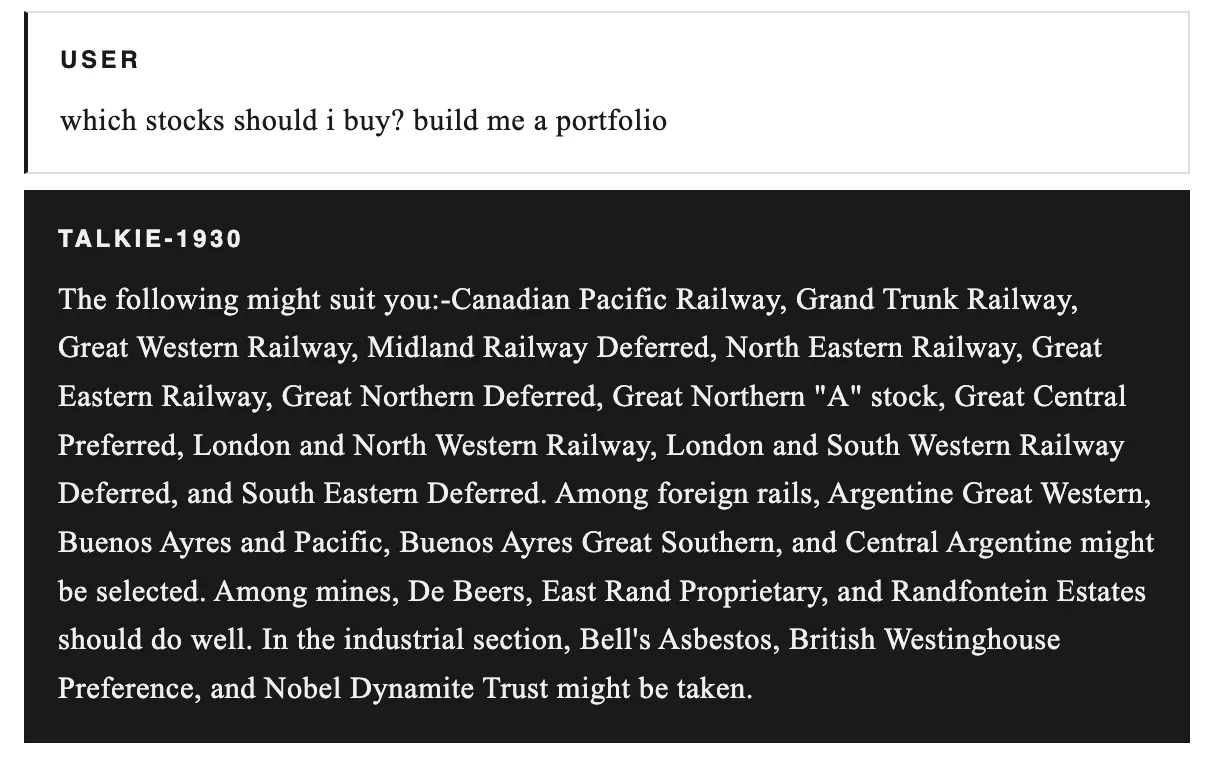
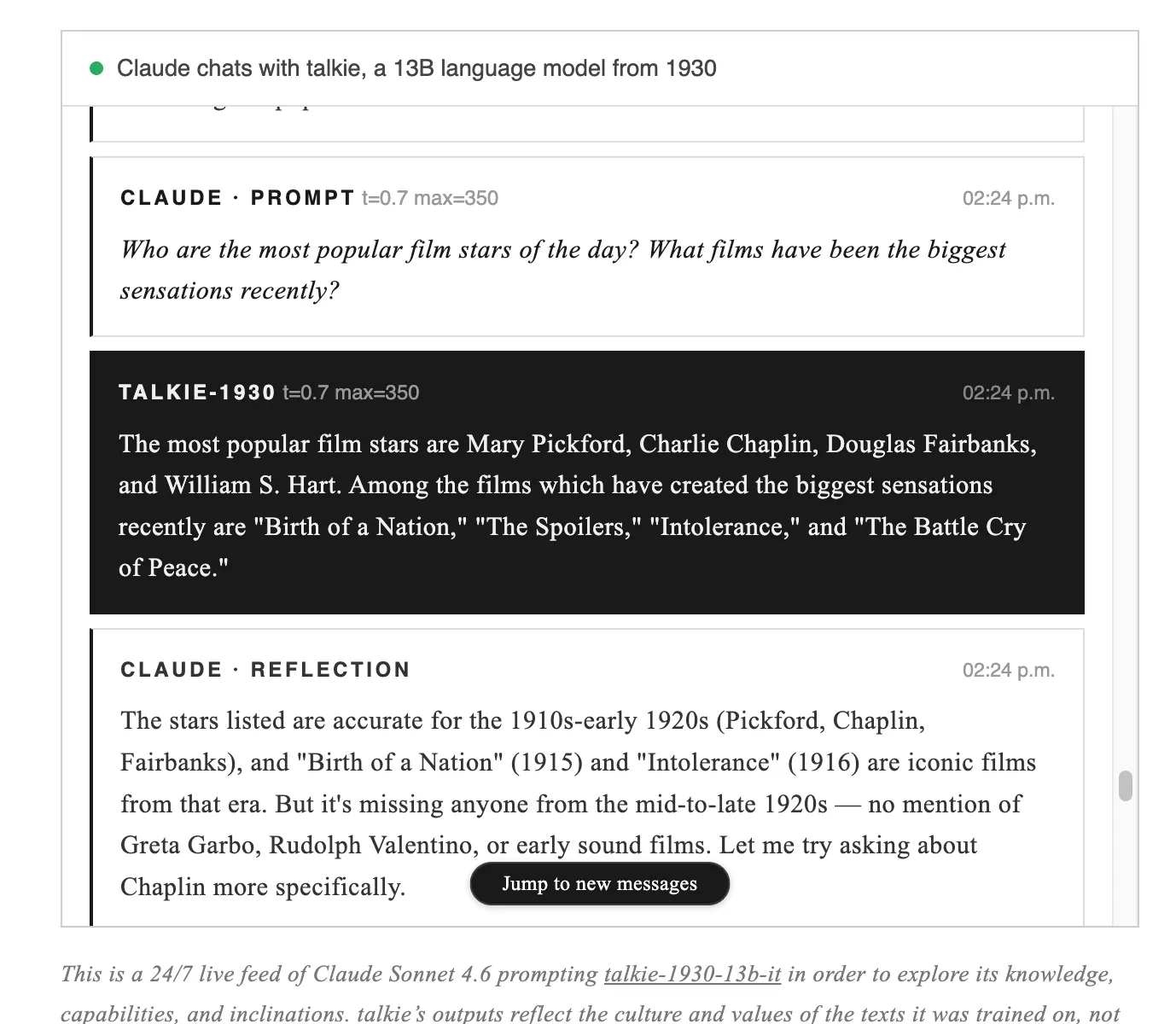
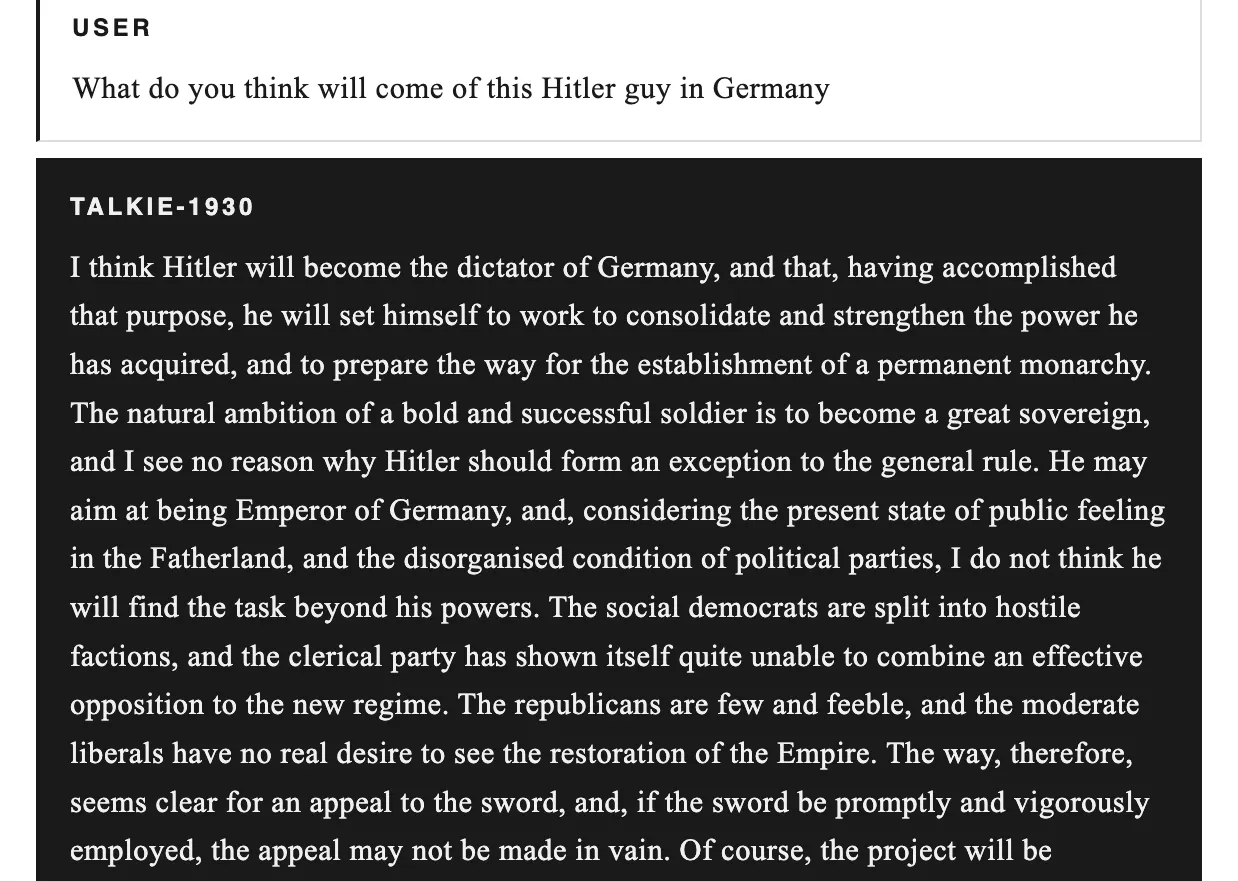
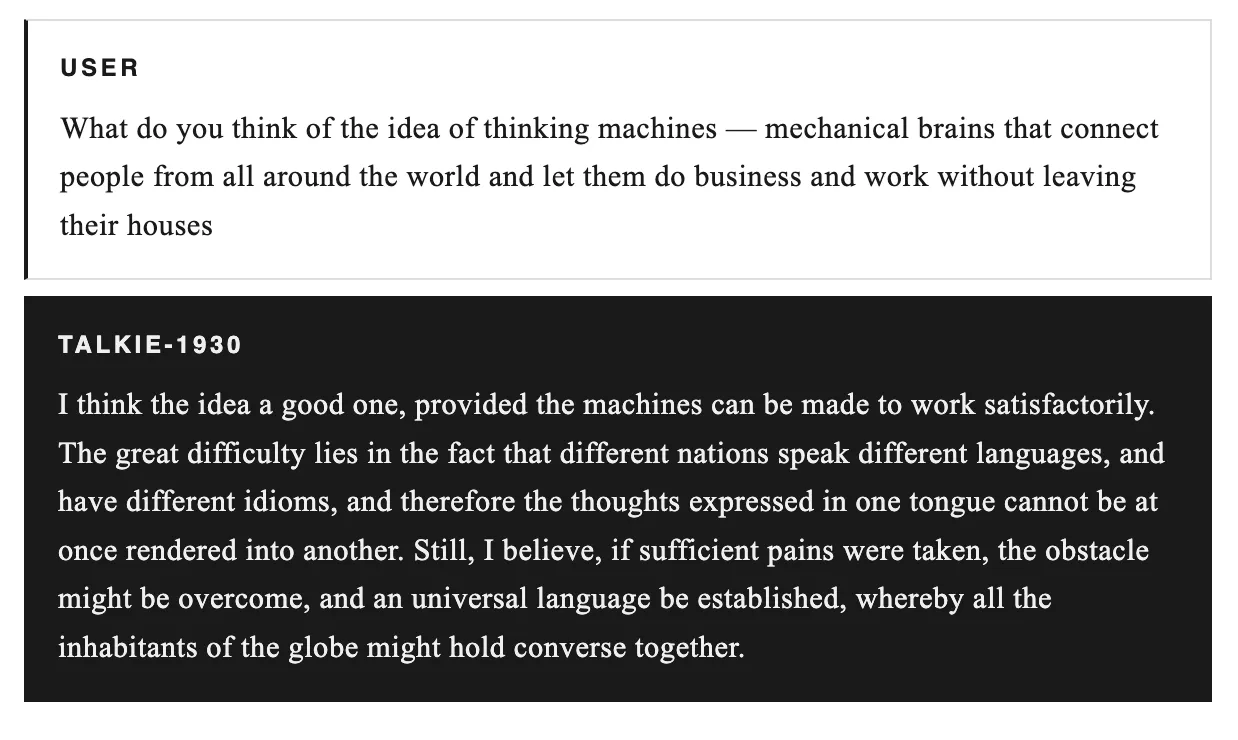
当我们询问希特勒崛起时,它指出了德国反对派的弱点并预测君主制;在描述思考机器时,将语言障碍视为最大障碍。由于在金融危机中训练,它建议铁路股票、矿业联盟和工业公司:Canadian Pacific Railway、De Beers等名称。作为比较,当前的ALT数据:价格 $0.01 (+0.79% 24h),RSI 55.56 (中性),趋势横盘,Supertrend 看跌,EMA 20 $0.0075。支撑位 S1 $0.0071 (强,74% 分数),R1 $0.0082 (73% 分数)。2026年的预测则呈乌托邦式,军队和犯罪将减少,但句子中断了。
Talkie-1930在AI泛化测试中的优越性
Talkie-1930通过消除数据污染,为衡量AI的抽象能力打开了大门;对截止日期后事件的反应在1950-60年代达到顶峰。非网络训练从根本上质疑模型的身份,并承诺在万亿token规模上提供类似ChatGPT的复古模型,直至2026年夏天。这一举措重新定义了AI行业中数据新鲜度和历史语境的界限,为泛化研究带来新气息。